

Python機械学習アルゴリズム学習備忘録。今回は線形判別分析 (Linear Discriminant Analysis)です。
内容は、Udemy の「【世界で74万人が受講】基礎から理解し、Pythonで実装!機械学習26のアルゴリズムを理論と実践を通じてマスターしよう」で学んだ内容を自分用備忘録としてまとめたものです。
参考
みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
【機械学習アルゴリズム学習備忘録】次元削減 – 主成分分析 PCA –線形判別分析の直感的な理解
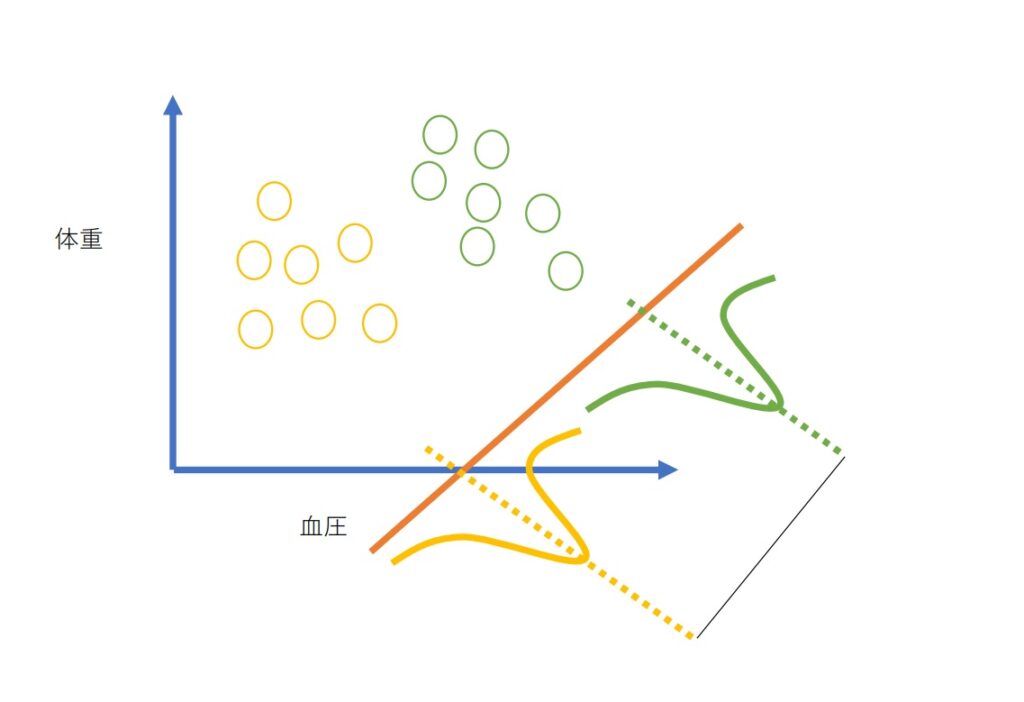
線形判別分析を直感的に理解するために、まず前提として、元々の対象データがある程度カテゴリ分けされているものとする。
追えば、体重と血圧のデータがあるとして、血圧が高い人=不健康な人、低い人=健康な人、というようなカテゴリ分けがされているとする。
(※あくまで直感的な理解のための仮定なので、実際の体重、血圧、健康度合いの相関性とは無関係です。)
グラフ上にそれぞれのデータがプロットされているとして、そのグラフに対して何らかの軸を取る。その軸の上で、データのクラスターごとの分布を取り、その分布の最も山の高いところ、つまり、最も数の多い部分どうしの距離が最大になるように軸を取る。その軸上にデータをプロットし直すことで、次元の削減ができる。
これが、線形判別分析の直感的なイメージ。
図で書くとこんな感じ。
Pythonによる実装
では、ここからPythonを使って、線形判別分析(Linear Discriminant Analysis)のコードを書いていく。
ライブラリのインポート
今回もまずはライブラリのインポートから。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdデータセットのインポート
次にデータセットのインポート。
dataset = pd.read_csv('Wine.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
フィーチャースケーリング
そして、フィーチャースケーリング。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = sc.fit_transform(X)訓練用とテスト用へのデータセットの分割
データセットの分割。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)LDAの適用
LDA (Linear Discriminant Analysis, 線形判別分析)を適用していく。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda = LDA(n_components=2)
# n_componentsは、いくつまで次元を削減するか、の指定。
X_train = lda.fit_transform(X_train, y_train)
X_test = lda.transform(X_test)
訓練用データセットを使ったロジスティック回帰モデルの訓練
ここからロジスティック回帰モデルを訓練していく。
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)テスト用データセットを使った結果の予測と混同行列の作成
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)訓練用データセットの結果の可視化
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend()
plt.show()テスト用データセットの結果の可視化
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Test set)')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend()
plt.show()こんな感じで、以上となります。
と詳しく学びたい方は、ぜひUdemyの講座を受講してみてください。



コメント