

Python機械学習アルゴリズム学習備忘録。今回はKernel PCAです。
内容は、Udemy の「【世界で74万人が受講】基礎から理解し、Pythonで実装!機械学習26のアルゴリズムを理論と実践を通じてマスターしよう」で学んだ内容を自分用備忘録としてまとめたものです。
参考
みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
【機械学習アルゴリズム学習備忘録】次元削減 – 主成分分析 PCA –
【機械学習アルゴリズム学習備忘録】次元削減 – 線形判別分析 Linear Discriminant Analysis –
Kernel PCAとは
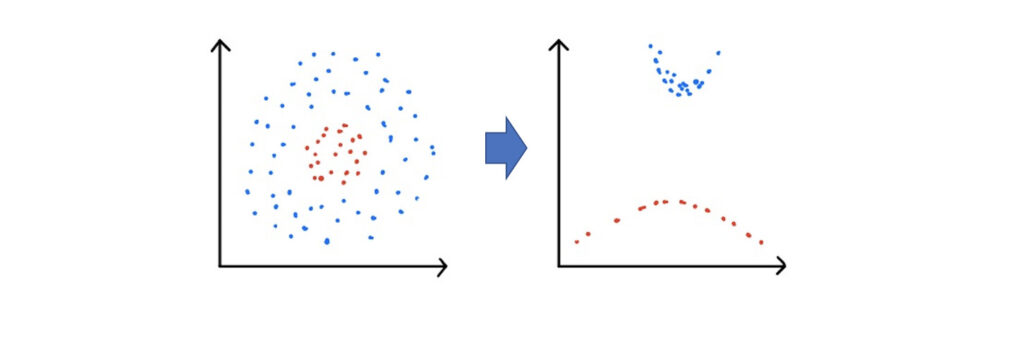
Kernel PCAとは、線形分離できないデータを特定の関数に入れることで、線形分離可能な状態に変換するために用いる考え方。
https://qiita.com/shuva/items/9625bc326e2998f1fa27
イメージとしては、上図のような感じ。
それぞれのクラスター内のデータのx, yの値を数式に入れ、値を変換する。この変換した値の距離に基づいてデータをプロットし直すことで、線形可能な形に変換することができる。
線形可能な状態に変換した上で、主成分分析を行っていく。
上に戻るPythonによる実装
ということでいつもの如くPythonで実装していく。
まずはインポート関係から。
ライブラリとデータセットのインポート
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('ファイル名.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
フィーチャースケーリングとデータセットの分割
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = sc.fit_transform(X)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
Kernel PCAの適用
次に、今回のテーマであるKernel PCAを適用していく。
from sklearn.decomposition improt KernelPCA
kpca = KernelPCA(n_components=2, kernel = 'rbf')
X_train = kpca.fit_transform(X_train)
X_test = kpca.transform(X_test)
# Kernel PCAを使って、新たにデータをプロットし、置き換えている。モデルの訓練と結果の予測
Kernel PCAを適用したデータセットを使って、モデルを訓練し、テスト用データで結果の予測をしていく。
# モデルの訓練
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)
# 今回はロジスティック回帰を用いていく。
# テスト用データセットを使った結果の予測と混同行列の作成
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)



コメント