

Python機械学習アルゴリズム学習備忘録。今回はグリッドサーチ(Grid Search)です。
内容は、Udemy の「【世界で74万人が受講】基礎から理解し、Pythonで実装!機械学習26のアルゴリズムを理論と実践を通じてマスターしよう」で学んだ内容を自分用備忘録としてまとめたものです。
参考
みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
【機械学習アルゴリズム学習備忘録】次元削減 – 主成分分析 PCA –
【機械学習アルゴリズム学習備忘録】次元削減 – 線形判別分析 Linear Discriminant Analysis –
グリッドサーチとは
グリッドとは、格子状のもののこと。
グリッドの網目に対応するハイパーパラメータの値があり、それぞれの組み合わせの場合の正確性などを求めて、一番精度の高い組み合わせを適用していく。
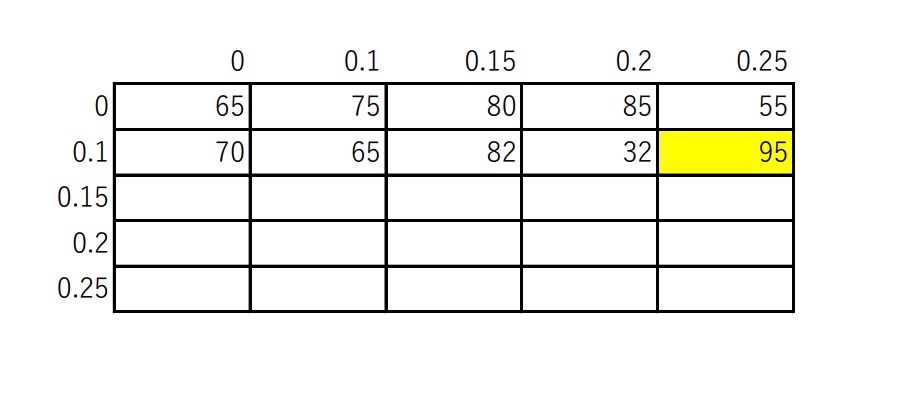
イメージとしては、上図のような感じ。数字は適当なものを入れてあるが、上辺と左辺にある値がハイパーパラメータの値、グリッドの中の値が正確性と考える。
上図の場合、黄色で示した部分が最も正確性が高く、良い組み合わせ、となる。
上に戻るPythonによる実装
ここからPythonでコードを書いていく。まずはいつもの流れから。
ライブラリのインポート
import numpy as np
import matplolib.pyplot as plt
import pandas as pdデータセットのインポート
dataset = pd.read_csv('ファイル名.csv')
X = dataset.iloc[:, [2,3]].values
y = dataset.iloc[:, -1].values
フィーチャースケーリング
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = sc.fit_transform(X)
# 今回はKernel SVMを使っていくので、フィーチャースケーリング必須訓練用とテスト用への分割
from sklearn.model_selection impot rain_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)訓練用データセットを使ったKernel SVMモデルの訓練
from sklearn.svm import SVC
classifier = SVC(kernel = 'rbf', random_state = 0)
classifier.fit(X_train, y_train)テスト用データを使った結果の予測と混同行列の作成
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)k分割交差検証の適用
まだ記事にしていないが、k分割交差検証というものがある。
詳細は別途記事作成予定。
k分割交差検証(k Fold Cross Validation)についてはこちらの記事を参照。
【機械学習アルゴリズム学習備忘録】Boosting – k分割交差検証 –
from sklearn.model_selection import cross_val_score
accuracies = cross_val_score(estimator = classifier, X = X_train, y = y_train, cv = 10)
print('Accuracy: {:.2f} %'.format(accuracies.mean()*100))
print('Standard Deviation: {:.2f} %'.format(accuracies.std()*100))Grid Searchの適用
from sklearn.model_selection import GridSearchCV
# ハイパーパラメータの格子(グリッド)の設定
parameters = [{'C':[1,10,100,1000], 'kernel':['linear']},
{'C':[1,10,100,1000], 'kernel':['rbf'], 'gamma':[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]}
]
grid_search = GridSearchCV(estimator = classifier,
param_grid = parameters,
scoring = 'accuracy',
cv = 10,
n_jobs = -1
)
# scoring : それぞれのハイパーパラメータの場合を評価する指標。
# 今回はaccuracyを基準に各パラメータの組み合わせを評価する。
# cv : データのバイアス等を避けるため、10階に分けて計算を行う。
grid_search = grid_search.fit(X_train, y_train)
best_accuracy = grid_search.best_score_
best_parameters = grid_search.best_params_
print("Best Accuracy: {:.2f} %".format(best_accuracy*100))
print("Best Parameters: ", best_parameters)
# 出力結果は↓こんな感じ
# Best Accuracy: 91.00 %
# Best Parameters: {'C': 1, 'gamma': 0.7, 'kernel': 'rbf'}
こんな感じでグリッドサーチ(Grid Search)を用いてよいハイパーパラメータの組み合わせを検証することができる。
上に戻る最後まで読んでいただきありがとうございました。では!



コメント